defavg_nosie(image): rows, cols = image.size pos = [] value = [] for i inrange(1, rows-1): for j inrange(1, cols-1): pos.append((i,j)) # 记录坐标,存入队列 val = 0 for m inrange(i-1,i+2): for n inrange(j-1, j+2): val += image.getpixel((m,n)) value.append(int(val/9)) # 计算像素平均值,存入队列 for i, j inzip(pos, value): image.putpixel((i,j)) # 根据记录的坐标队列和对应的像素值队列,重新写入图像像素数据 # 将上下边缘像素置为白色 for i inrange(cols): image.putpixel((0,i), 255) image.putpixel((rows-1,i), 255) # 将左右边缘像素置为白色 for i inrange(rows): image.putpixel((i,0), 255) image.putpixel((i, cols-1), 255) return image
defcut_noise(image): rows, cols = image.size change_pos = [] for i inrange(1, rows - 1): for j inrange(1, cols -1): pixel_set = [] for m inrange(i - 1, i + 2): for n inrange(j - 1, j + 2): if image.getpixel((m, n)) != 0: pixel_set.append(image.getpixel((m, n))) iflen(pixel_set) <= 5: change_pos.append((i, j)) for pos in change_pos: image.putpixel(pos, 0) return image
image = cut_noise(image) text = pytesseract.image_to_string(image, config='--psm 13') # 删除一些异常符号 exclude_char_list = ' .:\\|\'\"?![],()~@#$%^&*_+-={};<>/¥' text1 = ''.join([x for x in text if x notin exclude_char_list]) print(text1)



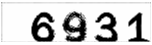 叠加后图片颜色黑白对比更加明显,但是中间白色噪点也更加突出。
叠加后图片颜色黑白对比更加明显,但是中间白色噪点也更加突出。 滤波后
滤波后